1. 필요 라이브러리
본 글에서 사용하는 라이브러리는 다음 3개이다.
requests
설치방식: pip install requests
BeautifulSoup4
설치방식: pip install beautifulsoup4
urllib3
설치방식: pip install urllib3
2. 구글 파이낸스(Google Finance) 구조 파악하기
구글 파이낸스에서 주가 정보를 끌어오려면 주가가 구글 파이낸스 사이트 어디에 위치하는지를 파악해야한다.
일단 구글 파이낸스 주소는 'https://www.google.com/finance/'이다. 사이트에 들어가면 다음과 같은 화면이 뜬다(아래 예시는 FireFox 브라우저를 쓴 예이다. Chrome 등 다른 브라우저를 써도 상관없다.)
이 중에서 우리가 가져올 주가는 KOSPI지수이다. 검색창에 'KOSPI'라고 검색하고 KOSPI를 찾아서 클릭하면 아래와 같은 화면이 뜬다.

여기에서 우리가 가져올 정보는 KOSPI라는 이름과 위 그림에서는 3,126.54로 표시된 현재가 정보이다. python 코드로 정보를 불러오려면 이 정보들이 사이트에 어떤 식으로 기록이 되어있는지를 파악해야 한다. 'KOSPI'라는 글자가 어디에 위치하는지 살펴보자.
우선 F12를 누른다(firefox, chrome 모두 마찬가지다)
그러면 아래와 같은 inspector 창이 뜬다.

inspector 좌상단의 보라색으로 표시된 버튼을 누른다. Firefox를 예로 들었지만 Chrome의 경우도 같은 위치에 저 화살표가 있다.
버튼을 누른 후에 마우스 커서를 'KOSPI' 글씨에 가져다 대면 화면이 아래와 같은 상태가 된다.

아래 빨간색 표시된 부분에 주목하자. 우리 눈에 큰 글씨로 보이는 'KOSPI'는 html상으로는
<h1 class="zzDege">KOSPI</h1>으로 작성되었다. 여기서 우리에게 필요한 정보는 'h1'과 'zzDege'이다.
혹시나 필요한 사람을 위해 부연설명을 하자면 h1은 header 1이라는 뜻이다. 한국어로는 '제목1'정도다. 위의 html을 해석하면 KOSPI라는 글자를 h1(제목1) 서식으로 표시하고 거기에 "zzDege"라는 이름을 붙여라이다.
같은 방식으로 보라색으로 표시된 버튼을 누르고 KOSPI 현재가 부분에 마우스를 가져다 대면 화면이 아래와 같은 상태가 된다.
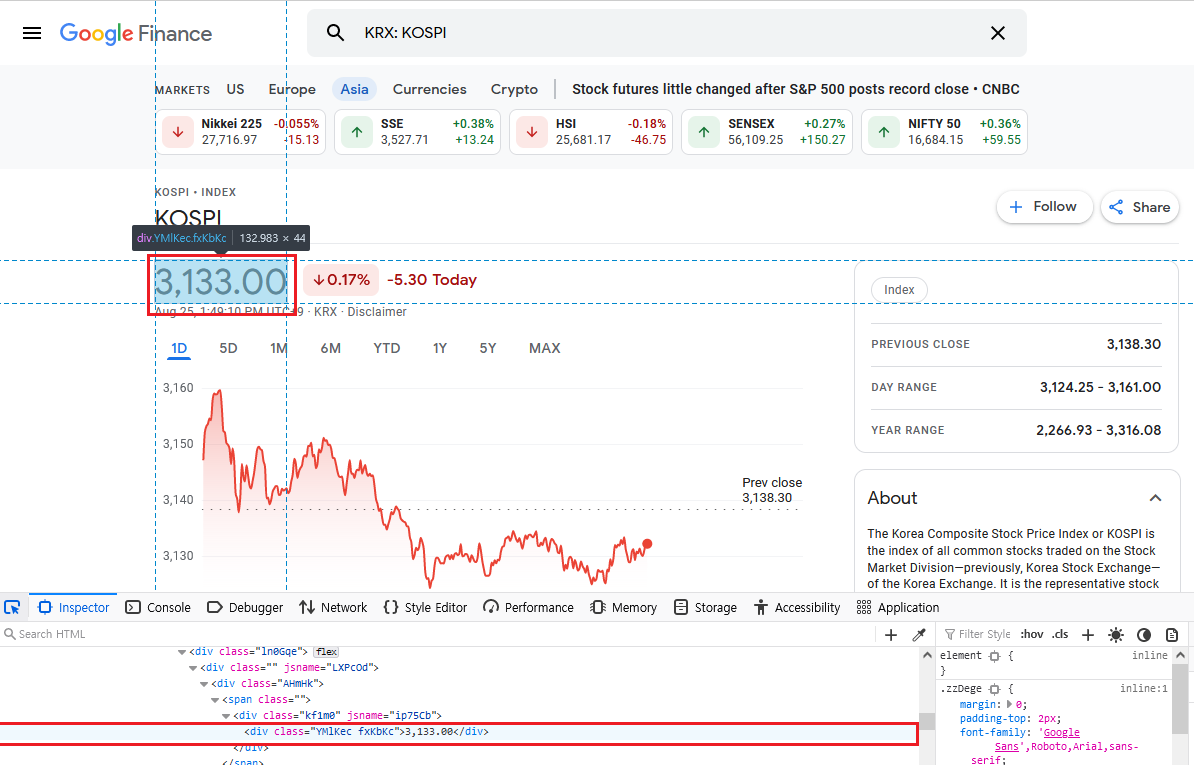
같은 방법으로 파악을 해 보면 KOSPI 현재가는,
<div class="YMlKec fxKbKc">3,133.00</div>로 기입되었음을 알게 된다. 여기에서도 우리에게 필요한 정보는 class정보인 div와 'YMlKec fxKbKc'다.
이 정도면 python 코드로 Google Finance에서 주가 정보를 불러오기 위한 사전 준비는 끝났다.
이제 코드를 작성하여보자.
3. Python 코드 작성
우선 전체 코드는 다음과 같다.
import requests
import urllib3
from bs4 import BeautifulSoup as soup
urllib3.disable_warnings()
baseurl = 'https://www.google.com/finance/quote/'
ticker = ['KOSPI:KRX', '.INX:INDEXSP', 'NI225:INDEXNIKKEI', 'SX5E:INDEXSTOXX']
nametag = 'zzDege'
indexvaluetag = 'YMlKec fxKbKc'
resultarray = []
for i in ticker:
pagehtml = requests.get(baseurl + i, verify=False)
pagehtmlbs = soup(pagehtml.text, 'html.parser')
idxname = pagehtmlbs.find('h1', class_=nametag).text
print('Index Name: ' + idxname + ' 입수완료.')
idxvalue = pagehtmlbs.find('div', class_=indexvaluetag).text
print('Index Value: ' + idxvalue + ' 입수완료.')
resultarray.append([idxname, idxvalue])
print(resultarray)이 코드를 하나하나 뜯어보도록 하자.
import requests
import urllib3
from bs4 import BeautifulSoup as soup위 코드는 import로 필요한 라이브러리를 불러온다.
세 번째 줄은 bs4(BeautifulSoup4) 라이브러리에서 BeuatifulSoup만 꺼내오되, BeautifulSoup은 타이핑하기에 너무 기니 'soup'이라고 줄여서 쓰겠다는 뜻이다.
urllib3.disable_warnings()위 코드는 url에서 페이지 정보를 부를 때 에러메세지를 무시하도록 만든다. 위 코드를 쓰지 않으면 'InsecureRequestWarning' 같은 경고 메세지가 뜬다. 경고 메세지가 떠도 코드는 실행되나 보기가 싫으므로 무시시키자.
baseurl = 'https://www.google.com/finance/quote/'
ticker = ['KOSPI:KRX', '.INX:INDEXSP', 'NI225:INDEXNIKKEI', 'SX5E:INDEXSTOXX']
nametag = 'zzDege'
indexvaluetag = 'YMlKec fxKbKc'
resultarray = []이 부분은 설정문이다.
위에 KOSPI 지수를 보는 화면을 살펴보면 사이트 주소가 'https://www.google.com/finance/quote/KOSPI200:KRX'이다.
즉 'https://www.google.com/finance/quote/' 밑에 주식 구분자가 붙는 식이다.
KOSPI든 S&P 500이든 NIKKEI225든 Eurostoxx 50이든 'https://www.google.com/finance/quote/' 까지는 똑같다. 그래서 이를 baseurl이라 설정하였다.
ticker부분은 baseurl 아래 부분들을 찾아서 기입했다. baseurl 뒤에 각 구분자들을 붙이면 각 지수의 종가 화면이 열린다.
nagetag과 indexvaluetag은 위에서 찾은 지수 이름과 현재가의 class name이다.
reseultarray는 우리가 웹사이트에서 받은 이름과 현재가 정보를 저장할 장소이다. 수집을 하기 전에는 아무 값도 없으므로 [](아무것도 없음)으로 설정하였다.
이제 본격적으로 python 코드를 통해 Google Finance 사이트에서 정보를 긁어보자.
아래 코드가 Google Finance에서 정보를 긁어오는 코드이다.
for i in ticker:
pagehtml = requests.get(baseurl + i, verify=False)
pagehtmlbs = soup(pagehtml.text, 'html.parser')
idxname = pagehtmlbs.find('h1', class_=nametag).text
print('Index Name: ' + idxname + ' 입수완료.')
idxvalue = pagehtmlbs.find('div', class_=indexvaluetag).text
print('Index Value: ' + idxvalue + ' 입수완료.')
resultarray.append([idxname, idxvalue])맨 윗줄부터 살펴보자.
for i in ticker:python의 장점 중 하나는 for문이 직관적이라는 점이다. 앞서 ticker 안에 4가지 주가지수 주소 정보를 기입하였다. 보통 for 문은 for 1 = 1 to 10 (1부터 10까지)식으로 쓰지만 python에서는 for i in ticker라고 쓰면 ticker안에 담긴 자료 하나하나를 차례로 꺼내온다.
위의 경우 i는 for문이 한 번씩 돌때마다 'KOSPI:KRX', '.INX:INDEXSP', 'NI225:INDEXNIKKEI', 'SX5E:INDEXSTOXX'로 차례대로 바뀐다.
pagehtml = requests.get(baseurl + i, verify=False)위 코드는 Google Finance 페이지 정보를 불러온다. requests라이브러리에는 get이라는 기능이 있고 이 기능은 입력된 url의 페이지 정보를 긁어온다. 뒤에 'verify=False'는 보안정보가 확인되지 않은 사이트여도 정보를 불러오라는 뜻이다. 이 구문을 빼먹으면 에러가 발생한다. Google Finance 사이트를 verify되지 않은 사이트로 여기기 때문이다.
좀 더 이해를 돕기 위해 첫 번째로 도는 for문에서 위 코드를 풀어 쓰면 어떻게 되는지를 예시로 들겠다.
baseurl ='https://www.google.com/finance/quote/'
i = 'KOSPI:KRX'
그러므로
baseurl + i = https://www.google.com/finance/quote/KOSPI:KRX
이 된다.
즉 위 코드를 다 풀어 쓰면
pagehtml = requests.get(https://www.google.com/finance/quote/KOSPI:KRX, verify=False)
가 된다.
위 코드를 실행하면 pagehtml에 'https://www.google.com/finance/quote/KOSPI:KRX'의 사이트 정보가 담긴다.
하지만 위 코드를 따로 실행해보면,

위와 같은 정보만 뜬다. 페이지 정보를 text로 보려면 'pagehtml.text'라고 치면 되는데 이를 실행하면 html 구문이 엄청나게 어지럽게 뜬다. 이래서는 자료를 쉽게 찾기가 힘들다. 따라서 자료를 깨끗하게 변환을 해주어야 한다.
다음 라인을 보자.
pagehtmlbs = soup(pagehtml.text, 'html.parser')여기에서 쓰인 soup이 바로 pagehtml.text를 정리해주는 기능이다. 뒤에 붙은 'html.parser'는 pagehtml.text를 html로 인식하고 예쁘게 정리하라는 뜻이다.
위 코드를 실행하고 'pagehtmlbs'를 실행하면 앞서 'pagehtml.text'보다는 정리가 된 결과가 나오지만 여전히 양이 너무 많다. 우리에게 필요한건 그 많은 라인 중 '지수 이름'과 '현재가'뿐이다. 찾아보자.
idxname = pagehtmlbs.find('h1', class_=nametag).text
idxvalue = pagehtmlbs.find('div', class_=indexvaluetag).text위 코드가 그 많은 html정보 중에서 우리가 원하는 '지수 이름'과 '현재가'를 찾아주는 코드이다.
pagehtmlbs에는 아까 보았듯 수많은 html 정보가 담겼다. .find 는 특정한 무언가를 찾아주는 함수이다.
잠시 아까 Google Finance 사이트 분석을 했을 때 찾은 html라인을 상기시켜보자
<h1 class="zzDege">KOSPI</h1>우리는 pagehtmlbs가 담은 수많은 html 정보 중 '지수 이름'에 한해서는 위 한줄만이 필요하고 위 한 줄 찾기가 목적이다. 이것을 .find 함수가 해준다.
즉, pagehtmlbs.find('h1', class_=nametag).text는,
pagehtmls에 담긴 html중에 서식이 'h1'이고 class name이 nametag(zzDege)인 줄을 찾아서,
text만 따로 떼어주는(.text의 기능이다) 코드이다.
그 다음줄도 같은 원리로 수많은 html라인중에 현재가 정보를 찾아서 text만을 찍어준다.
그러므로 위 코드 실행 결과 idxname에는 'KOSPI'가, idxvalue에는 현재가 정보가 들어가게 된다.
이 정보들을 저장해주지 않은 채로 for문이 돌아가게 되면 이 정보는 날아간다. 그래서 이 정보를 저장해주어야 하는데,
resultarray.append([idxname, idxvalue])이 코드가 그 일을 해준다.
여기서 .append는 ( ) 안 정보를 추가하라는 뜻이다.
마지막 줄인
print(resultarray)는 결과를 눈에 보이게끔 출력(print)하라는 코드이다.
그리하여 전체 코드를 실행하면 다음과 같은 결과가 뜬다.

다음 글에서는 PyQt6를 활용하여 주가지수를 불러오는 어플리케이션을 만드는 방법을 올려보도록 하겠다.
'Python' 카테고리의 다른 글
| 파이썬(Python): 클래스(class) 안 def __init__(self): 와 self 등을 제대로 이해하기 (10) | 2022.08.16 |
|---|---|
| PyQt5와 PyQt6의 미묘한 차이들 (0) | 2021.08.18 |
| 라이브러리(library)란 무엇일까? (6) | 2021.08.16 |


댓글